Extracting Statistics from Source Code
Topics
This week’s assignments will guide you through the following topics:
- Computational concerns of creating graphs from Smali
- Using graph statistics as features (and using these for EDA).
Reading
Please read the following:
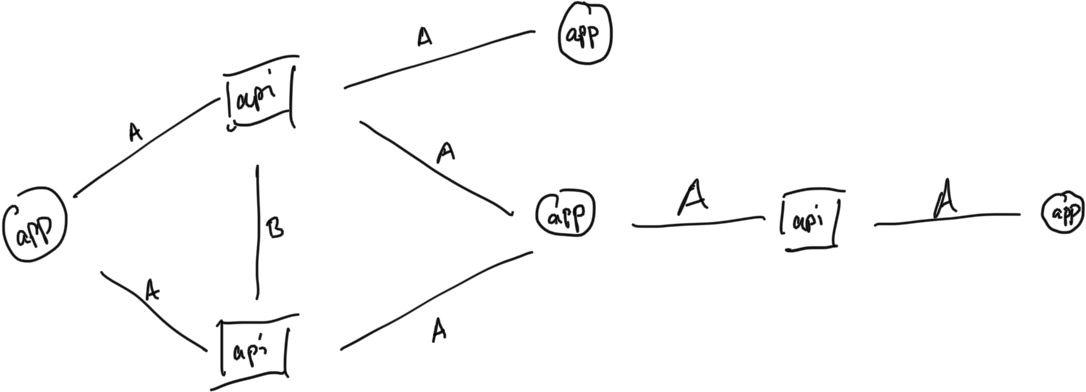
- (Re)Read HinDroid sections 3.1 - 3.2 (Features & HIN construction).
- From the
/teams/DSC180A_FA20/a04malwaredirectory, run the commandls -l malware/ | shuf | head -3. This will pull 3 Malware types at random. Google them and try to find out what they do.
Bonus:
- Read MaMaDroid (Sections I, IIABC). This paper uses something closer to an n-gram approach to source code in the same setting.
Tasks
Complete the following tasks:
- Continue work on the ETL pipeline (work on the larger dataset)
- Complete an EDA on (a sample of) the app dataset in the
/teamsdirectory. You should be aiming to answer questions:- how do the apps differ for Malware vs Not? Different types of Malware? Random vs. Popular apps?
- which classes in an app ‘add no new information’? How might you extract data from a subset of the smali files in an app?
- From the EDA, you’ve likely computed a table where the observations are apps and the columns are statistics for that app. Use this to train/test a baseline classifier (e.g. using Logistic Regression). This will serve as a basis for later comparison.
Weekly Questions
Answer the following questions on Canvas:
- Give a summary of a Malware type in the training data that you researched. What does it do? How does it work?
- Give an interesting observation from your EDA. Be specific, with precise values!
- What features did you use in your baseline model? What was the model performance?
- What difficulties did you encounter that you would like to discuss this week?